Chapter 15.1 - Introduction to Graph Databases and NEO4j
Contents
Chapter 15.1 - Introduction to Graph Databases and NEO4j#
Authors: John Erol Evangelista
Maintainers: John Erol Evangelista
Version: 0.1
License: CC-BY-NC-SA 4.0
Graph Databases#
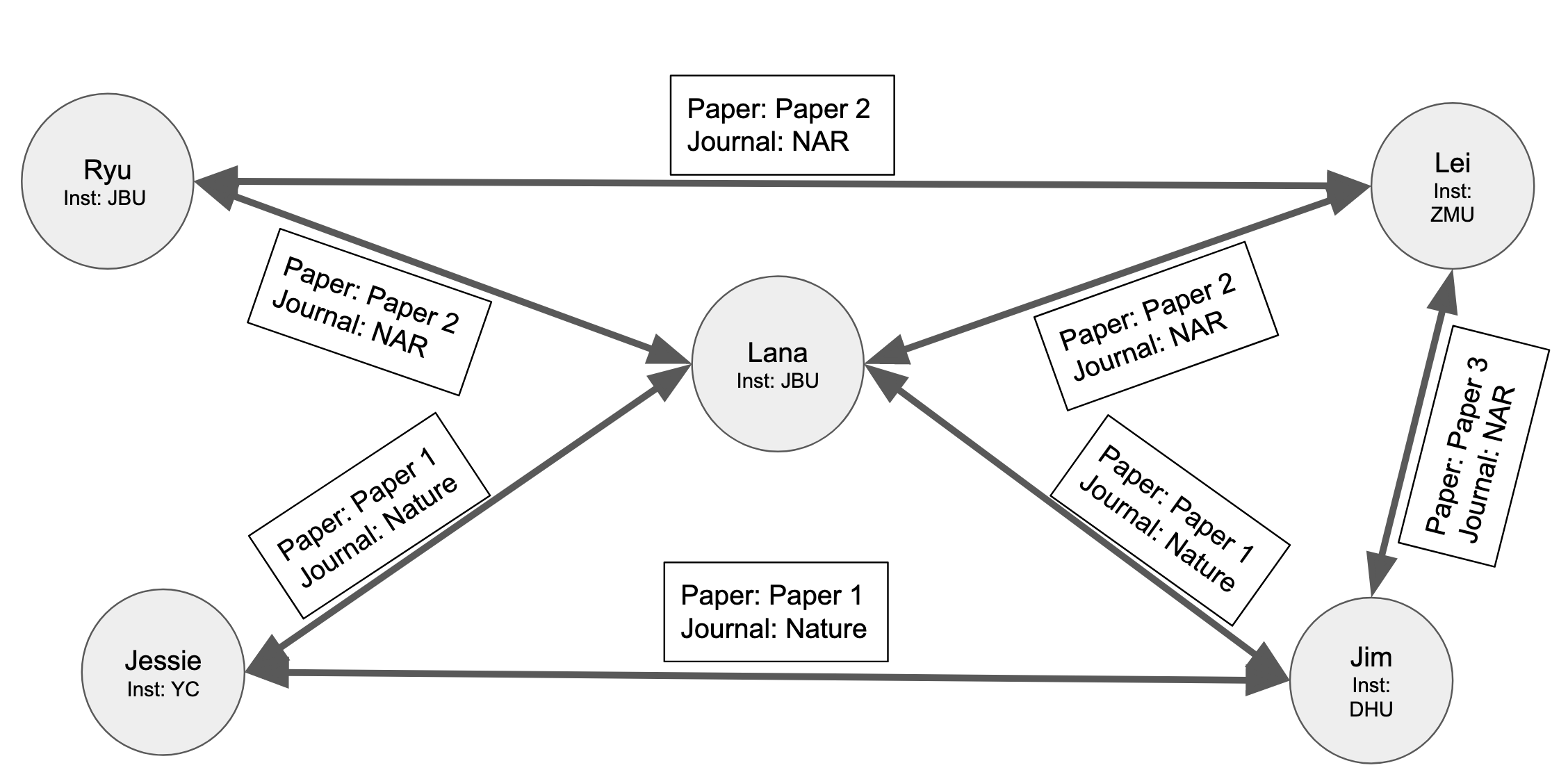
Fig. 15 Collaborators in a graph database#
Graph Databases store information differently compared to relational databases. In Graph Databases the connections are stored as a graph, or a network. Each node is an author, and we also have the institution as metadata for the nodes Fig. 15. The links indicate collaboration between two authors. The relationships also list the paper both authors worked on together and the journal where they published their work. Graph Databases store entities as nodes and the connections between these entities. We can then resolve database queries with graph traversal algorithms.
So finding “which authors have collaborated with both Jessie and Lei” is as simple as traversing the graph to find a path of length 2. Graph Databases are optimized for these types of queries. So it is easier and faster to find connections between nodes compared to traditional relational database systems. Traditional relational database systems may work better than Graph Databases for other types of queries.
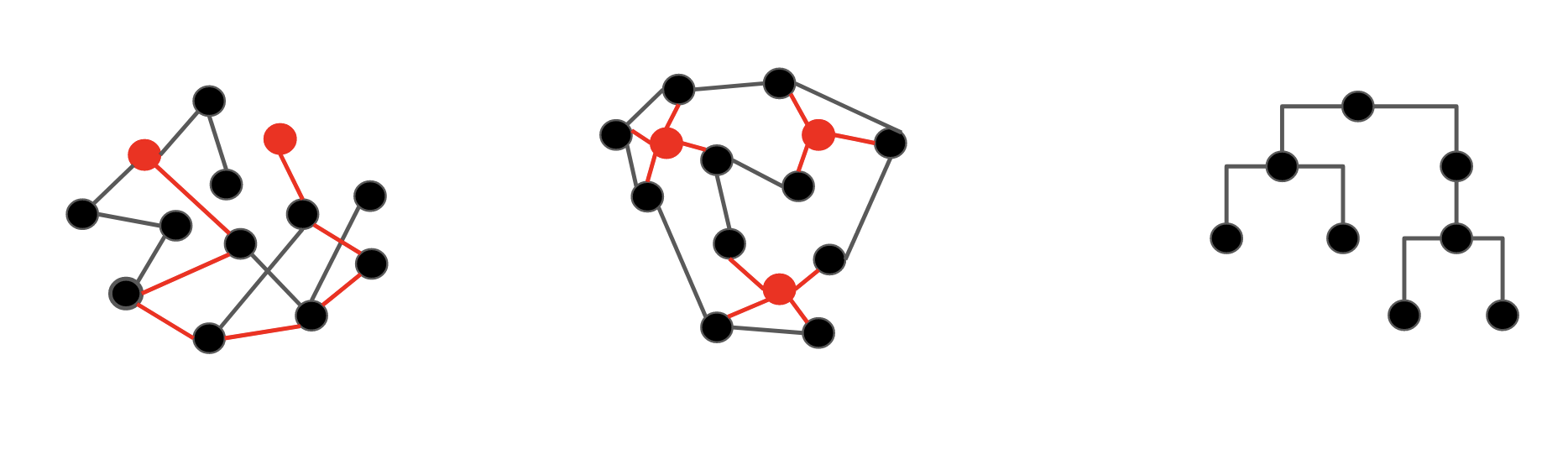
Fig. 16 Graph Databases make it easier to find hidden connections between entities#
Overall, Graph Databases make it easier to find hidden connections between entities. This use case is not as straightforward if we are using a relational database. Graph Databases are effective for discovering hierarchies, finding paths and patterns between nodes, and optimized for many-to-many queries.
With all their benefits, Graph Databases are not without disadvantages. First, we’ve mentioned that we have a standardized query language for relational databases, which makes it easy to work with different RDBs. Graph Databases don’t have a standard query language yet. Each implementation can have its own query language, which can be a barrier for many developers and users since they must learn a new language. Languages like SPARQL and OpenCypher exist, but they are not considered a standard language for Graph Databases.
NEO4j#

Neo4j is a leading open-source NoSQL native Graph Database. Native means that the database stores the data in graph-like data structures. Non-native graph databases may store data in a relational database but use a NoSQL query implementation on top of it. So why we decided to use Neo4J for our applications. First, we learned previously that Graph Databases don’t have a standardized query language. Neo4J’s graph query language, Cypher, is a leading language that is supported by several other graph database providers and the OpenCypher project. We will discuss Cypher in more detail in the next lecture. Cypher syntax is very intuitive. Neo4J has efficient implementations of graph traversal algorithms. The graph property schema in Neo4J is flexible, making it easy to add new edges and nodes. Last, Neo4J also has multiple drivers built for different programming languages making it easy to integrate Neo4J into other programming projects.
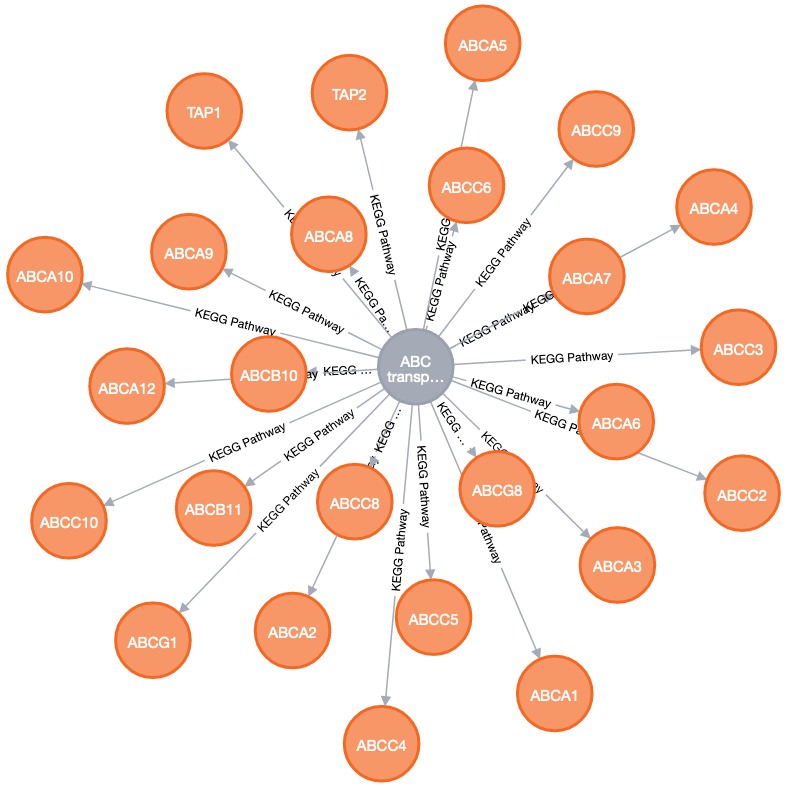
Fig. 18 NEO4j graph depicting the 25 genes associated with ABC transporters.#
Let’s now look at the property graph model of Neo4J. Graphs are made of two parts: nodes and edges (Fig. 18). Typically, nodes represent entities and the edges the relationships between these entities. Nodes have labels that define their type. In this example, we have the two nodes that represent authors. Nodes can also have properties and can be indexed and constrained to improve performance. Edges or relations can have directionality. In other words, we define a source node and a target node. Relationships can also have properties. Importantly, nodes can have multiple edges without affecting the performance of the database, making it ideal for querying many-to-many relationships.
In the next section we’ll look at how to start your own Neo4j instance.