Chapter 16.1a - Introduction to Machine Learning
Contents
Chapter 16.1a - Introduction to Machine Learning#
Authors: Daniel J. B. Clarke
Maintainers: Daniel J. B. Clarke
Version: 0.1
License: CC-BY-NC-SA 4.0
Background#
What is Artificial Intelligence (AI)?#
Any algorithm implemented in machines which demonstrates human-like intelligence. For example:
Speech to Text
Recommendation Systems
Path Finding

What is Machine Learning (ML)?#
ML is a popular way to achieve AI which uses data-driven algorithms. Models are a product of architecture and data . Some examples include:
Image Recognition
Natural Language Processing (NLP)
Reinforcement Learning (RL)
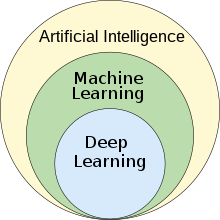
What is “Deep” Learning?#
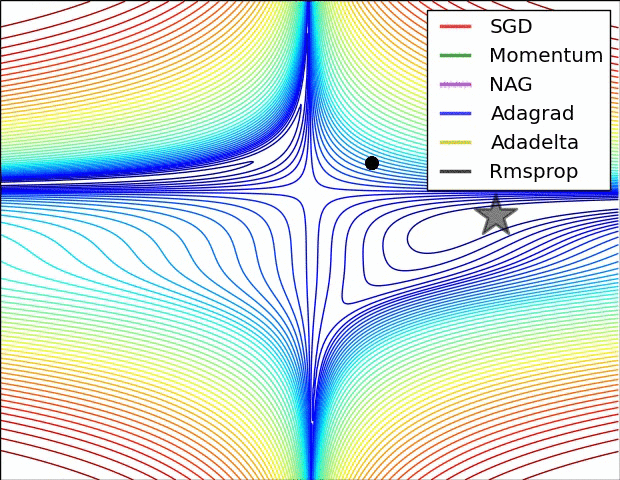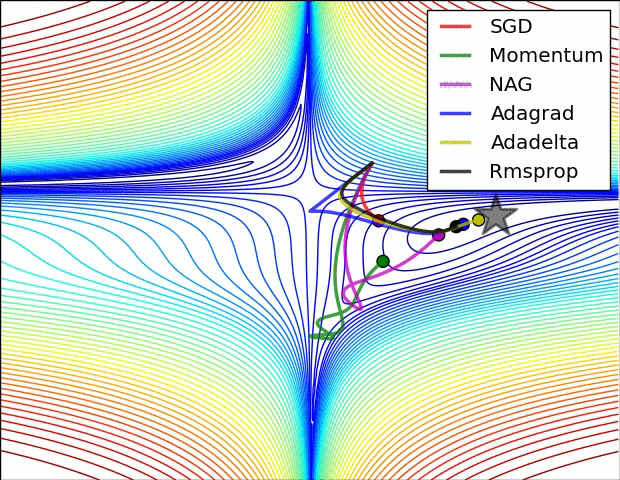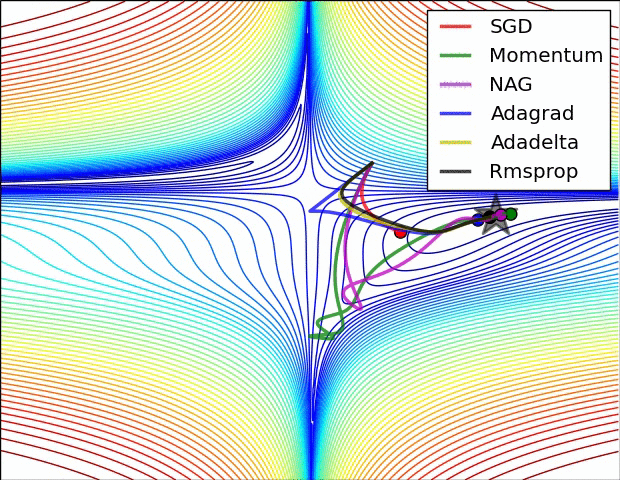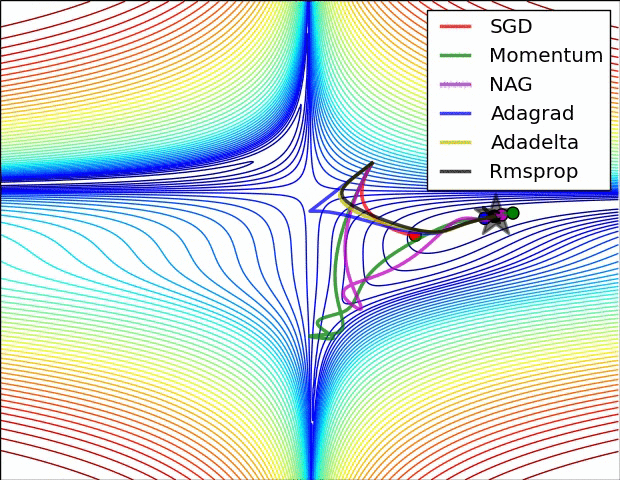
Deep learning refers to ML with extremely high number of parameters typically tuned (or learned) by gradient descent on lots of data. Examples of Deep Learning Models include:
Alpha Zero - Super-human Shogi, Chess, and GO
GPT-3 - Large Language Model
Alpha Fold - Protein Structure Prediction
DALL-E 2 - Text to Image

Machine Learning in Practice#
Data Preparation : Find, then Extract, Transform and Load (ETL)
Data Normalization: Distribution of your data should be known, typically normal
Data Exploration : Unsupervised methods and visualization
Model Selection : Select the model which best fits the data at hand
Model Tuning and Cross Validation : Optimize the models performance on your data and test it on data the model has never seen before.
Scrutinize & Refactor : Good results should make you nervous, identify potential information leakage and try again. Bad results means you might try a different model.
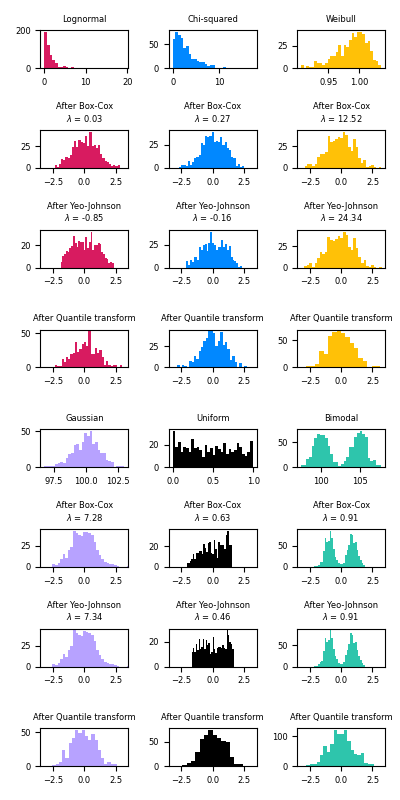
Data Normalization#
Most models expect data to be “normal” – N(0,1)
Real data often follows a different distribution which can be transformed (Fig A).
Different normalization may be required depending on your data’s distribution and presence of outliers (Fig B).

High Level Types of Machine Learning Approaches#
Supervised Learning
Train a model to predict the label of new unseen samples using many paired labels and samples.
E.g. Linear Regression, Decision Trees,Feed Forward Neural Networks, etc.
Unsupervised Learning
Train a model to label or organize samples without known labels.
E.g. Clustering, Decomposition,Anomaly Detection, etc.
Semi-supervised Learning
Train a model with some labeled samples and many unlabeled samples to predict labels of unseen data.
E.g. Transfer Learning, Energy Based Models, etc..
Reinforcement Learning
Train a model to select the best action in a given state to maximize a reward.
E.g. Policy Learning, Q Learning,Actor Critic, etc.
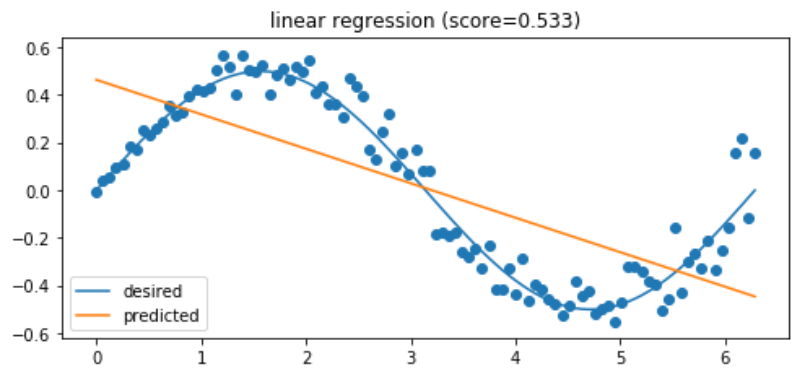
Regression vs. Classification#
Regression: Output variable is continuous.
Classification: Output variable is discrete.
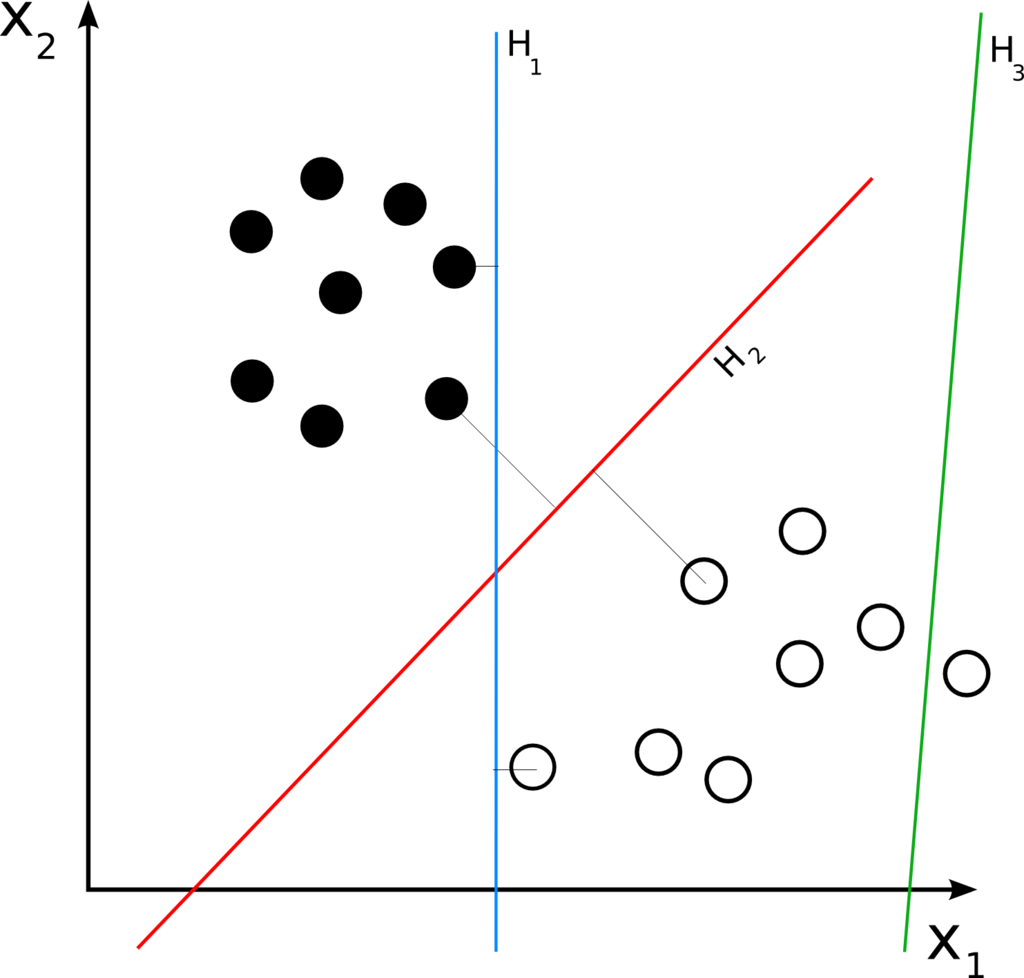
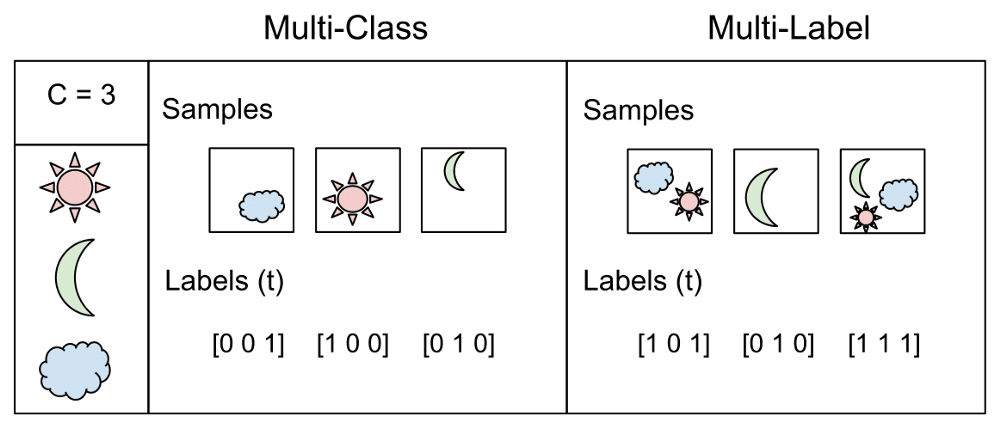
Models#
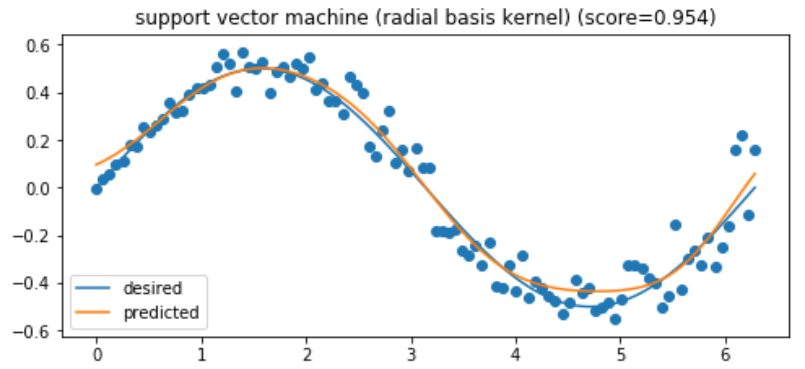
Supervised Learning: Linear Models#
Linear models are heavily used in statistics and are applicable whenever the output variable is linear or a prior distribution is known (allowing you to linearize your otherwise non-linear data).
Algorithms of note include:Linear Regression: for continuous output.Logistic Regression for binary output.ElasticNet: A linear regression with an L1/L2 penalty on weights for robustness.


Unsupervised Learning: Dimensionality Reduction#
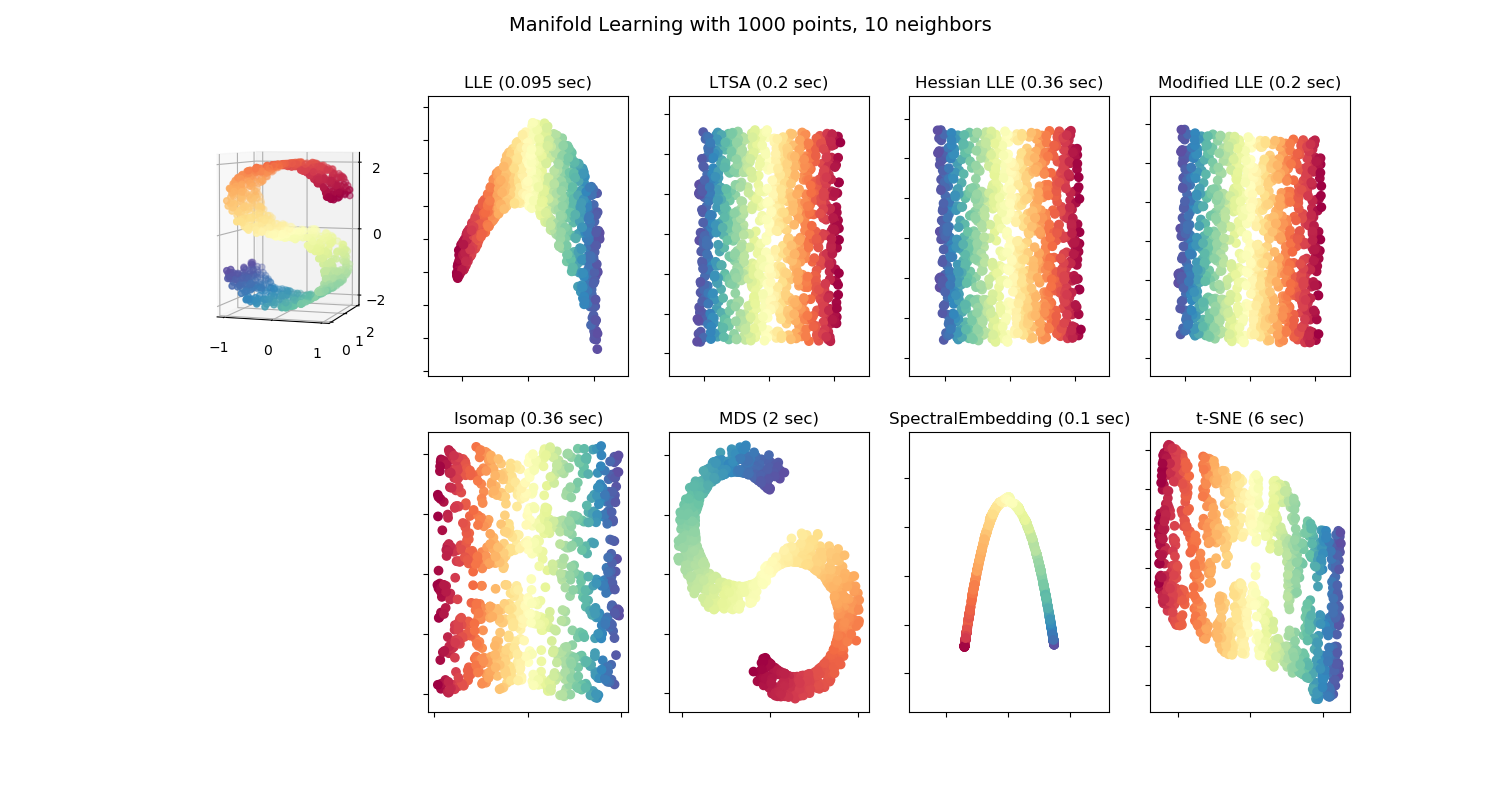
Project high dimensional data into lower dimensions for visualization or for computational tractability.
Algorithms of note include:
Principal Component Analysis (PCA): Linearly transform data such that the highest dimensions of covariance are captured in the first few dimensions (Fig B).
t-distributed Stochastic Neighbor Embedding (t-SNE) & Uniform Manifold Approximation and Projection (UMAP): non-parametric methods to preserve sample neighbors from the original space in the projection space (Fig C).


Unsupervised Learning: Clustering#
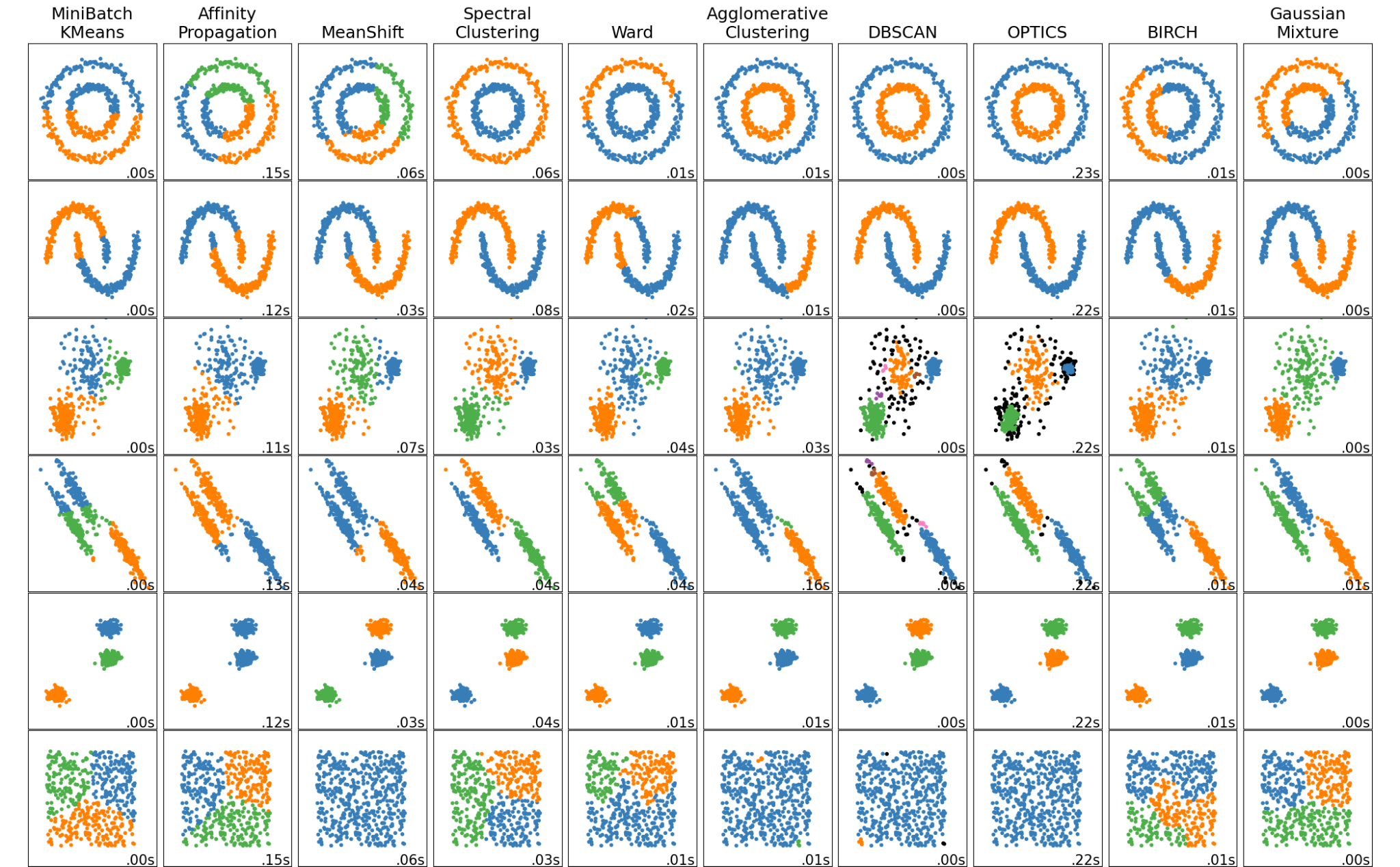
Assign labels to data based on sample proximity. Different sense of “proximity” is more meaningful for different types of data, hence the different algorithms.
Algorithms of note include:
K-Means: Points closest to K maximally separated centroids.
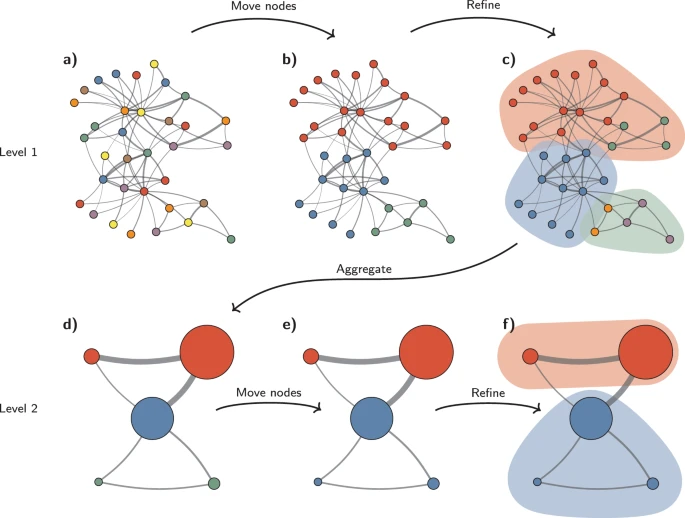
Leiden: Community detection, relevantfor biological networks (Fig C).
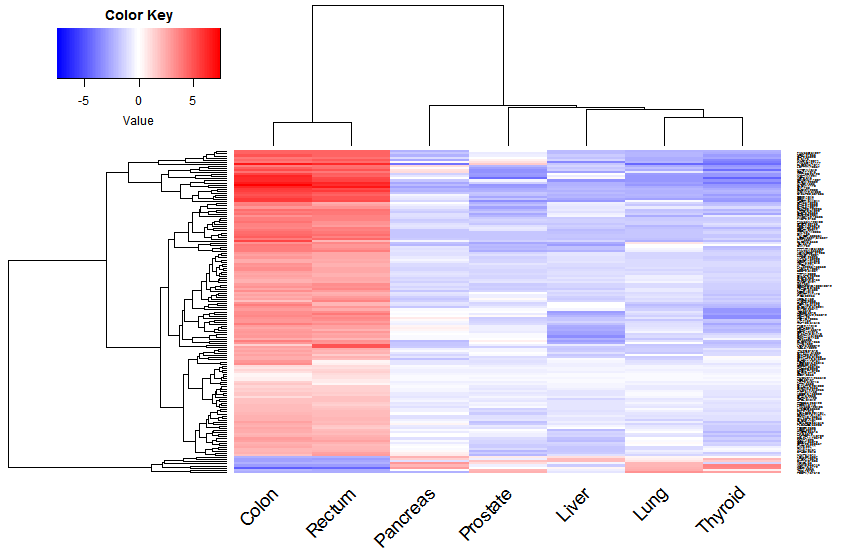
Hierarchical Clustering: Widely usedin transcriptomics (Fig B).
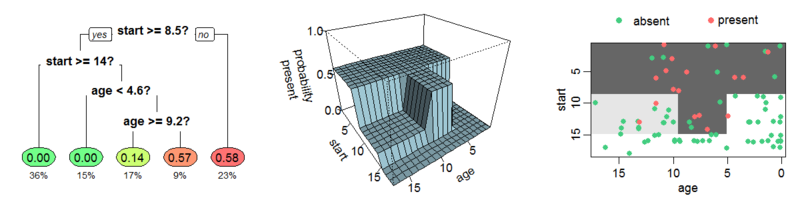
Supervised Learning: Decision Trees#
Many more parameters than Linear models. Powerful and typically more interpretable than e.g. Deep Learning, but still have limitations.
Algorithms of note include:
Decision Trees: Each split in the tree is a classification on one dimension.
Random Forest: Many randomly constructed decision trees vote on the answer.
XGBoost: Use gradient descent to find the best weights to assign to each tree’s answer.
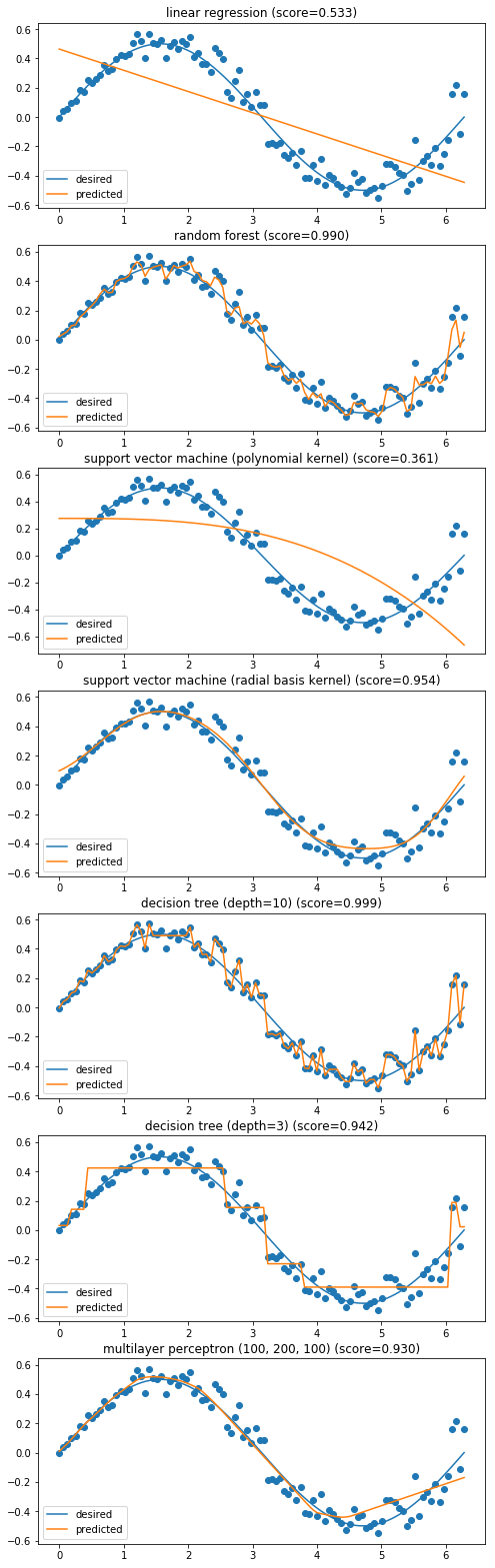
ML In Practice#
Benchmarking#
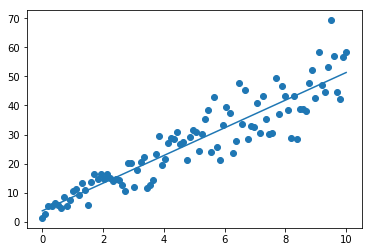
Regression Metrics : Quantifying the prediction error we have:
Mean Squared Error (MSE): square to penalize the negative/positive error equally (Fig A). Root Mean Squared Error (RMSE) is just the square root of this.
Coefficient of Determination (R2): proportion of predictable variation from statistics (Fig B).
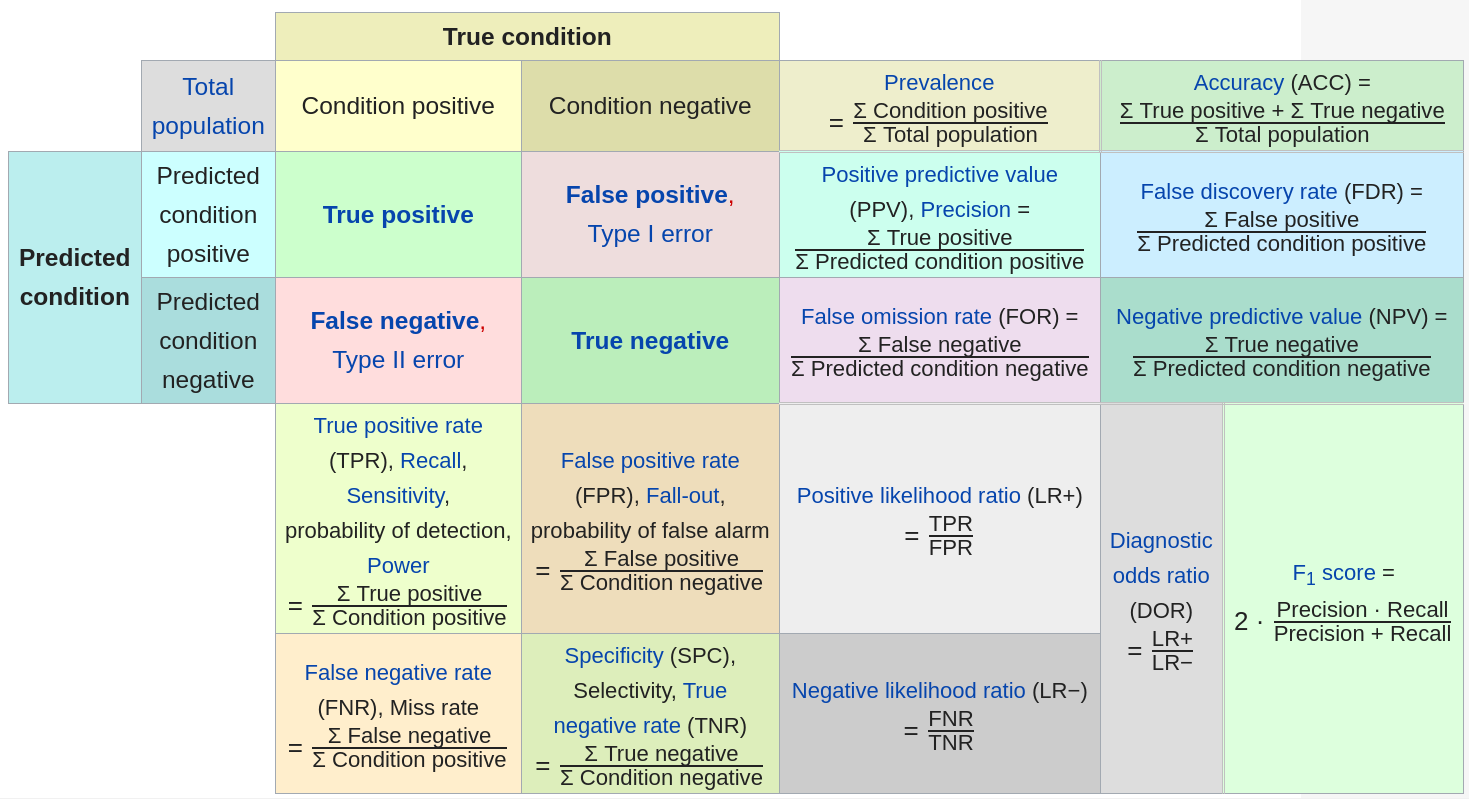
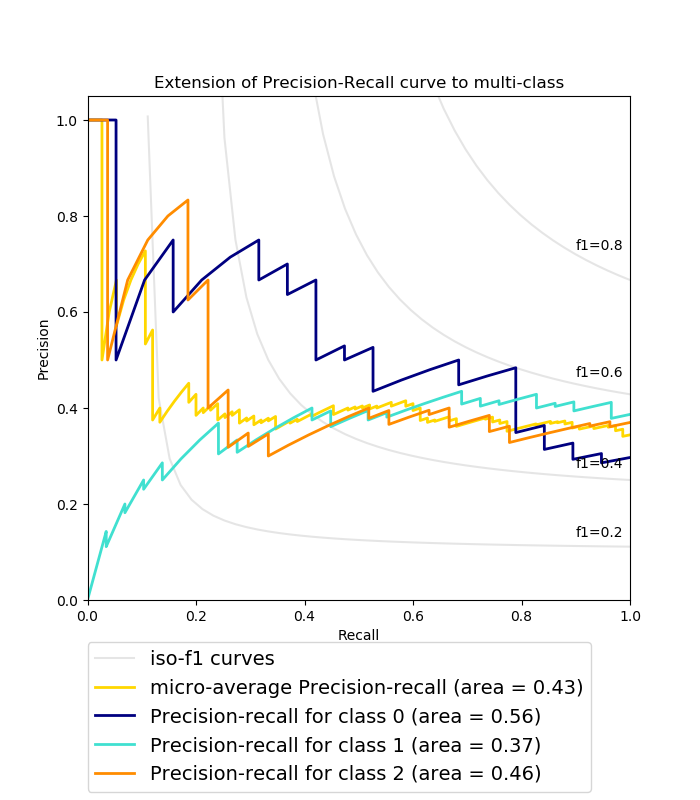
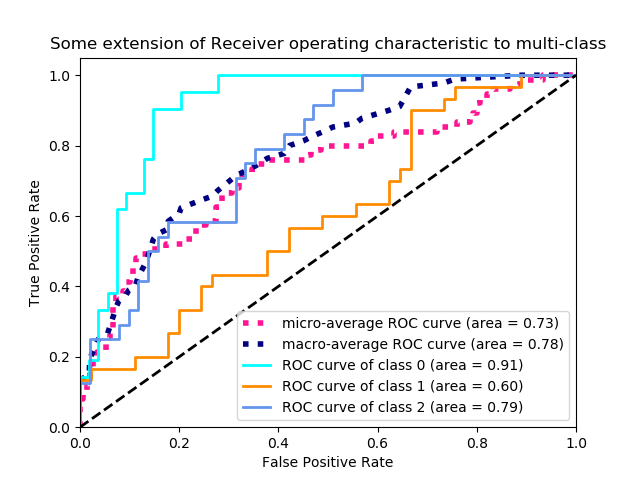
Classification Metrics : Classification performance has many metrics all to turn 4 numbers (True pos/neg, False pos/neg) into 1 (Fig C).
We can typically tune a classifier to trade off precision and recall achieving a desired FDR.
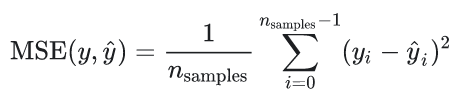
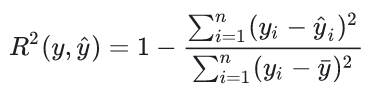
Receiver Operating Characteristic (ROC)#
A classifier typically assigns a probability to each point, the cutoff can be tweaked (Fig A) having an effect on the results (Fig B).
The ROC Curve shows TPR and FPR for all choices of cutoff (Fig C).
The PR Curve shows Precisionand Recall for all choices of cutoff (Fig D).
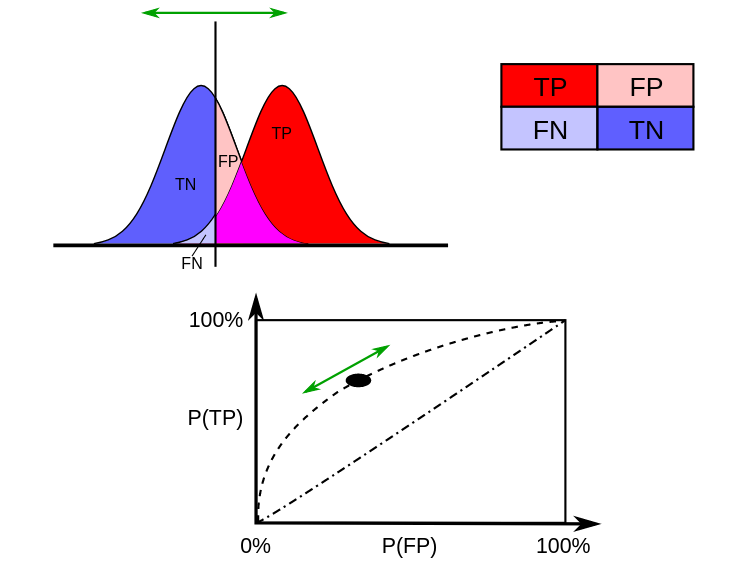
Confusion Matrix
Cross Validation#
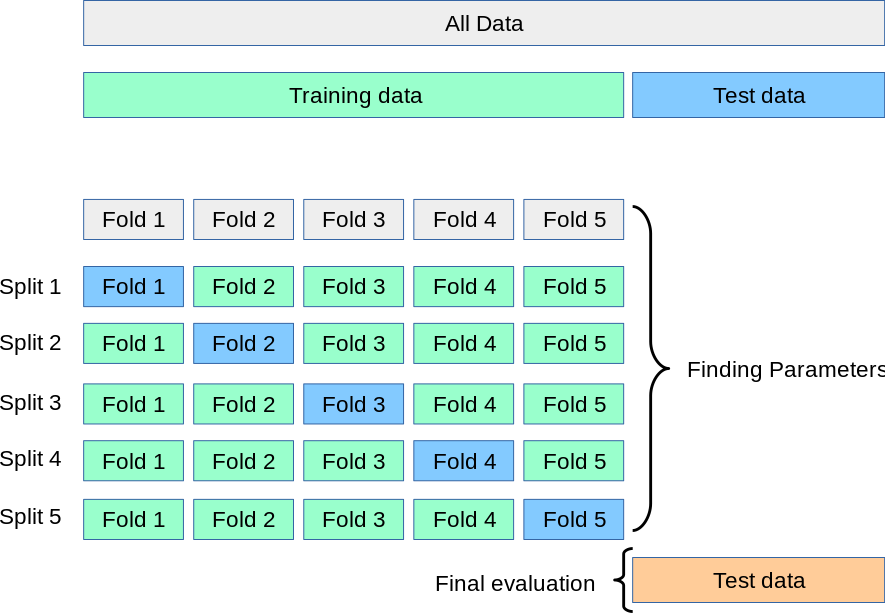
Ensure your model generalizes to unseen data. The model should be tuned on segments of the data it’s never seen before, and evaluated on data never used in tuning.
k-Fold Cross Validation (shown): split data into K segments and alternate which segment is used for testing.
Stratified Shuffle Split: preserve (possibly imbalanced) class distribution in splits.
Random Shuffle Split
Scikit-Learn#
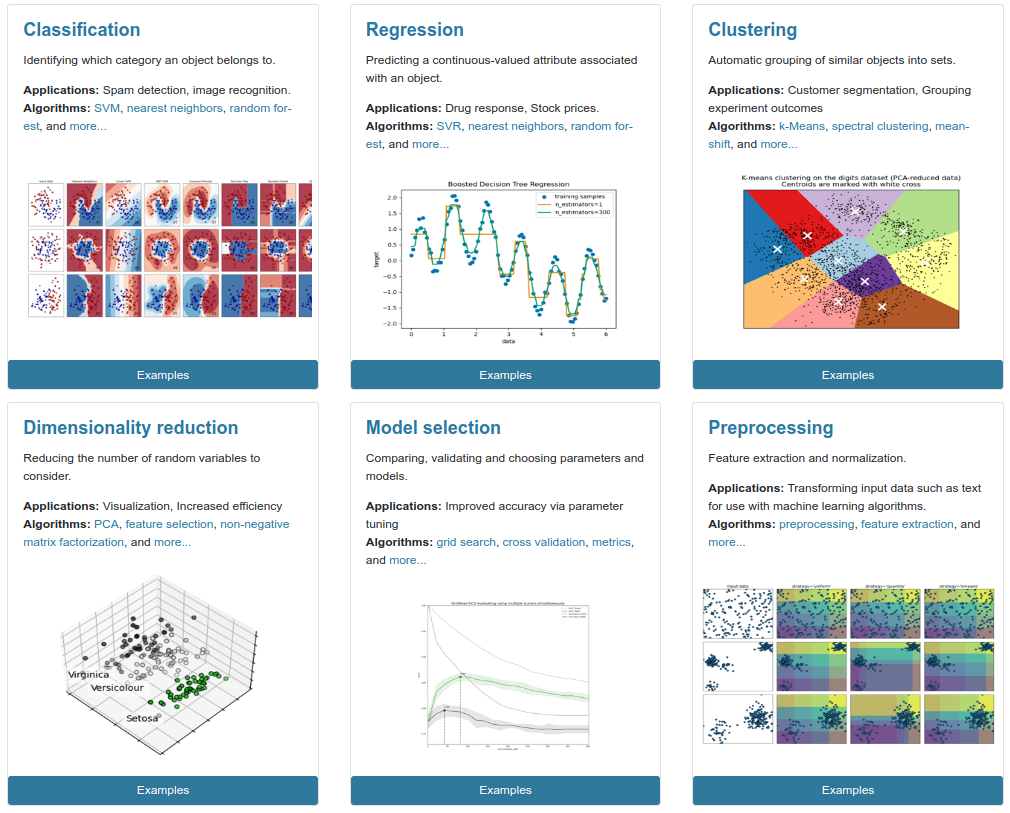
Scikit-Learn is a Python library of ML implementations part of the SciPy scientific computing ecosystem in Python. Many third party models also interoperate with Scikit-learn.
Their docs & user guide have citations, explanations and example code for every aspect of practical ML.
https://scikit-learn.org/stable/index.html

Conclusions#
In this lecture we learned about
Definitions & Terminology including
AI, ML, Deep Learning
Supervised, Unsupervised, Semi-supervised, Reinforcement Learning
Regression; Binary, Multi-class, Multi-label Classification
Various classes of models
Linear Models
Dimensionality Reduction
Clustering
Decision Trees
ML In Practice
Normalization
Regression, Classification Metrics
Cross Validation
Scikit-Learn
Next Time: Deep Learning#
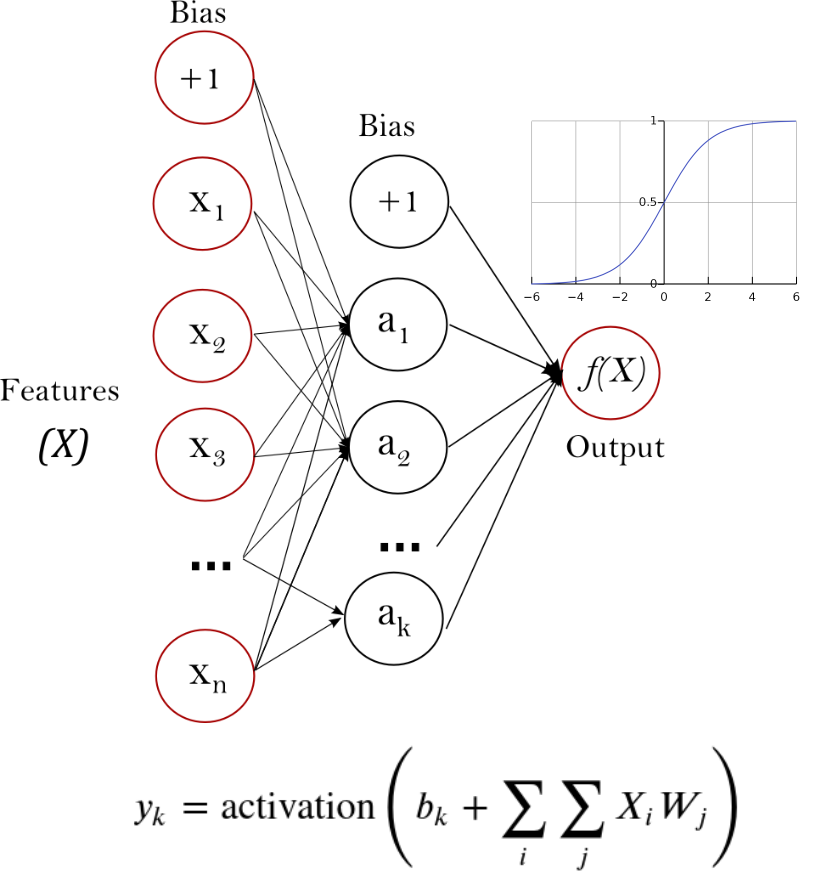
Experiential Learning#
Machine Learning Practicum